


💡 병렬화 및 내결함성의 세부 사항을 추상화하는 대규모 데이터셋을 처리하기 위한 프로그래밍 모델
Cluster
Master Node
분산 파일 시스템을 관리하고 워커 노드가 수행할 작업을 예약한다.
- NameNode: 파일 시스템 메타 데이터를 관리
- Job Tracker: 워커 노드에서 작업 실행을 조정
Worker Node
데이터를 처리하는 작업을 실행하는 시스템이다. 데이터 블록을 저장하고 마스터노드로부터 할당된 테스크를 수행한다. 하둡에서 데이터는 분산된 방식으로 워커 노드에 저장된다. 맵리듀스 모델은 그 데이터를 병렬 처리하는데 쓰인다. 이런 원리로 하둡은 대용량 데이터를 효율적으로 관리하고 데이터 분석과 머신러닝 같은 규모의 작업을 할 수 있다.
Job
클라언트가 수행하는 작업의 기본 단위 (입력 데이터, 맵리듀스 프로그램, 설정 정보)
Map
데이터셋의 각 개별 레코드에 map function을 적용하여 입력 데이터를 중간 키-값 쌍 세트로 변환한다.
입
Reduce
key-value 쌍은 동일한 키와 관련된 모든 값을 결합한다.
데이터 흐름
하둡에서는 맵리듀스 잡의 입력을 스플릿(고정 크기 조각)으로 분리한다. 각 스플릿마다 하나의 맵 태스크를 생성하고 스플릿의 각 레코드를 사용자 정의 맵 함수로 처리한다.
전체를 한번에 처리하는 것보다 스플릿으로 분리된 많은 조각을 각각 처리하는 것이 훨씬 빠르다.
맵리듀스를 통해 좋은 성능을 내는 과정도 스플릿을 병렬로 처리하여 고성능 서버가 저성능 서버보다 더 많은 스플릿을 처리할 수 있기 때문에 스플릿의 크기가 작을 수록 부하 분산이 더 좋다. 이러한 부분은 같은 성능의 서버에서도 프로세스가 실패하거나 여러 잡이 동시에 실행되기 때문에 부하 분산은 중요하다. 반면 스플릿 크기가 너무 작으면 스플릿 관리와 맵 태스크 생성을 위한 오버헤드 때문에 잡 태스크의 실행 시간이 증가한다는 단점이 있다. 일반적으로 HDFS 블록의 기본 크기인 128MB가 적당하다. 그 이유는 128MB가 단일 노드에 저장되는 가장 큰 입력 크기이다. 하나의 스플릿이 두 블록에 걸쳐 있을 때 두 블록 모두 저장하는 경우는 거의 없다. 이 경우 스플릿의 일부 데이터를 네트워크를 통해 맵 태스크가 실행되는 다른 노드로 전송해야하는데 맵 태스크 전체가 로컬 데이터만 이용하는 것보다 더 느려지게 된다.
맵 태스크의 결과는 HDFS가 아닌 로컬 디스크에 저장된다. 맵의 결과는 리듀스가 최종 결과를 생성하기 위한 중간 결과물이다. 잡이 완료된 후 맵의 결과는 그냥 버려지게 된다. 따라서 맵의 결과를 HDFS에 저장하는 것은 내부 복제 과정을 추가하는 것이며 적절치 않다. 리듀스 태스크로 모든 결과를 보내기 전에 맵 태스크가 실패한다면 하둡은 자동으로 해당 맵 태스크를 다른 노드에 할당하여 맵의 출력을 다시 생성할 것이다.
리듀스 태스크는 일반적으로 모든 매퍼의 출력 결과를 입력으로 받기 때문에 데이터 지역성의 장점이 없다. 일반적으로 리듀스의 결과는 안정성을 위해 HDFS에 저장된다. 리듀스 출력에 대한 HDFS 블록의 첫번째 복제본은 로컬 노드에 저장되고, 나머지 복제본은 외부 랙에 저장된다. 따라서 리듀스의 결과를 출력하는 것은 네트워크 대역폭을 소모하지만 일반적인 HDFS 쓰기 파이프라인에 소모되는 대역폭과 비슷한 수준이다.
데이터 지역성 최적화
하둡은 HDFS내의 입력 데이터가 있는 노드에서 맵 태스크를 실행할 때 가장 빠르다. 이는 클러스터의 중요한 공유 자원인 네트워크 대역폭을 사용하지 않는 방법이다.
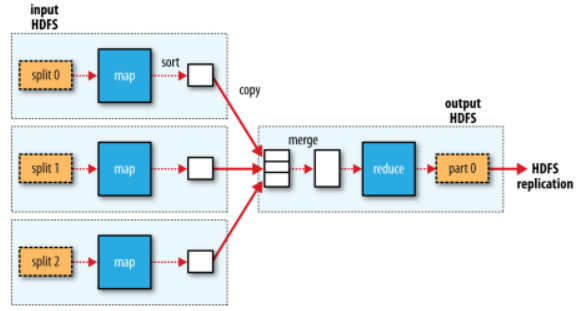
)
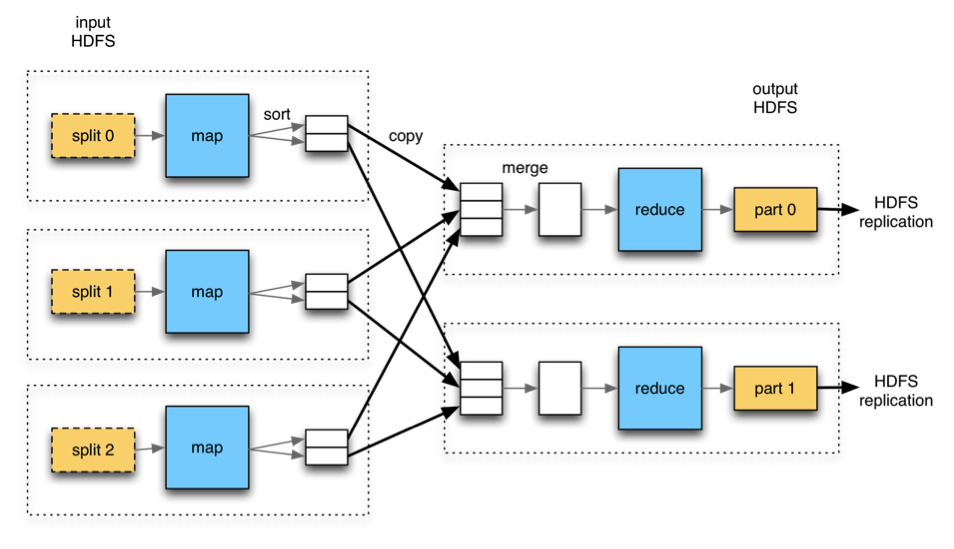
리듀스가 다수이면 맵 태스크는 리듀스 수만큼 파티션을 생성하고 맵의 결과를 각 파티션에 분배한다. 각 파티션에는 여러 키가 존재하지만 개별 키에 속한 모든 레코드는 여러 파티션 중 한 곳에만 배치된다. 주로 해시 함수로 키를 분배하는 기본 파티셔너를 사용한다.
리듀스 수를 선택하는 것으로 잡의 실행 시간에 미치는 영향이 매우 크기 때문에 튜닝이 필요하다.

리듀스 태스크가 아예 없을 수도 있다. 셔플이 필요 없고 모든 처리 과정을 완전히 병렬로 처리하는 경우 (유일한 외부 노드 간의 데이터 전송은 맵 태스크가 그 결과를 HDFS에 저장하는 경우) 적합하다.
Spark이랑 뭐가 다른가?
Apache Spark and MapReduce are both frameworks for processing large datasets, but they have some important differences:
- Speed: Spark is generally faster than MapReduce for most workloads, due to its in-memory computing model and use of a cache.
- Programming model: Spark has a more flexible programming model than MapReduce, as it supports a wide range of operations beyond map and reduce, including transformations, actions, and streaming. MapReduce, on the other hand, is limited to the map and reduce functions.
- Data storage: Spark can read data from a variety of sources, including HDFS, HBase, Cassandra, and S3, while MapReduce is limited to reading data from HDFS.
- Cluster management: Spark has its own cluster manager, while MapReduce relies on an external system such as YARN or Mesos.
Overall, Spark is generally considered to be more powerful and flexible than MapReduce, but it may not be the best choice for every use case. It is important to evaluate the specific requirements of your application before deciding which framework to use.
'DataEngineering' 카테고리의 다른 글
| Spark tuning (0) | 2024.03.17 |
|---|---|
| [Spark] Spark run in Cluster Mode-YARN (1) | 2024.02.04 |
| [Airflow] Operators (0) | 2024.01.21 |
| Airflow Concept (0) | 2023.12.24 |
| Hadoop (0) | 2023.01.07 |