

이번 포스트에서는 Spark 작업을 최적화하여 성능을 향상시키는 방법에 대해서 다룹니다. Spark 성능 튜닝은 시스템이 사용하는 메모리, 코어와 인스턴스를 대상으로 기록할 설정을 조정하는 프로세스를 가리킵니다. Spark 튜닝을 통해 편의성과 성능 사이의 균형을 맞추고 리소스 병목 현상을 예방하는 효과를 얻을 수 있습니다.
Data Serialization
객체를 직렬화하는 부분에서 성능에 영향이 크기 때문에 Spark 어플리케이션 최적화를 위해 가장 먼저 조정합니다. 여기서 직렬화를 다루는 이유는 직렬화는 spark은 네트워크로 데이터를 전송하거나 디스크에 쓸 때 바이너리 포맷으로 변환하기 위한 과정이나 셔플과정에서 쓰이기 때문에 이부분 튜닝이 성능에 큰 영향을 줄 수 있습니다. spark에서는 java, Kryo 직렬화 라이브러리를 제공합니다. Kryo 직렬화가 Java 직렬화보다 10배정도 빠르게 직렬화할 수 있지만 모든 유형을 지원하지는 않으며 사용할 클래스를 미리 등록해야하는 사용자 정의 등록이 요구됩니다. 반면 java 직렬화는 유연하지만 느릴 수 있습니다.
Memory Tuning
데이터 처리 시 약속한 것 이상으로 메모리를 사용하게 될 시 다음 다음 에러와 요구사항을 확인할 수 있습니다.
Container killed by YARN for exceeding physical memory limits. Consider boosting spark.executor.memoryOverhead.메모리 사용량 튜닝을 위해서는 다음 고려사항을 확인해야합니다.
- 객체로 사용될 메모리
- 해당 객체에 접근하는 비용
- Garbage collection overhead 비용
여기에서 Java 객체에 접근하는 것은 빠르지만 Java 문자열은 내부적으로 인코딩을 사용하여 원시 문자열 데이터보다 약 40 바이트의 오버헤드가 발생하거나 일반적인 컬렉션 클래스는 연결된 데이터 구조로 헤더 뿐만 아니라 포인터도 갖는 등 raw 데이터에 비해 2-5배 더 많은 공간을 소비할 수 있습니다.
따라서 메모리 관리에 대해서 다룬 다음 어플리케이션에서 데이터 구조를 변경하거나 데이터를 직렬화된 형식으로 저장해서 메모리 사용량을 확인하고 개선할 수 있습니다.
메모리 사용 정의하기
공식문서에서는 메모리 사용을 확인하는 가장 좋은 방식은 RDD를 생성하고 캐시에 넣어 Spark-Storage UI에서 확인하는 방법을 제안하고 있습니다. 이를 통해서 해당 RDD가 차지하고 있는 메모리를 확인할 수 있습니다.

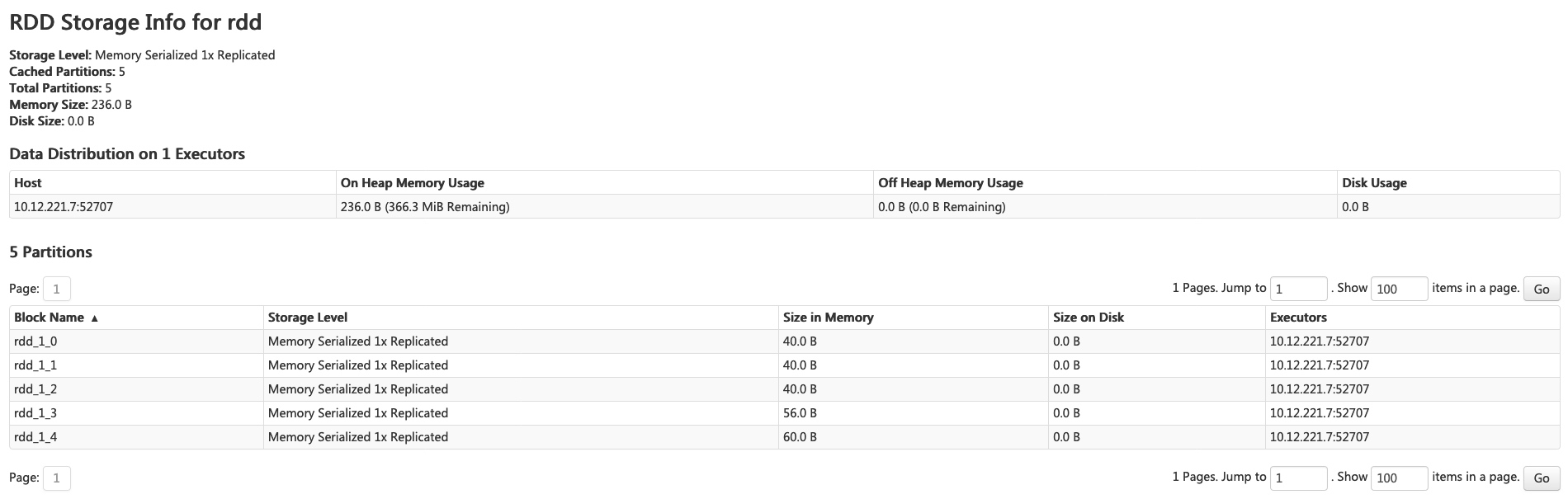
스토리지 수준, 파티션 수, 메모리 오버헤드와 같은 기본 정보가 제공됩니다. 하지만 새로 생성된 RDD는 materialized되기 전에 확인하기는 어렵습니다.
특정 객체에 대한 메모리 사용량을 측정하기 위해서는 SizeEstimator클래스의 메서드를 사용할 수 있습니다.
import org.apache.spark.util.SizeEstimator
SizeEstimator.estimate(df)- web ui, SizeEstimator 사용 비교에 대한 글
web UI와 SizeEstimator로 반환된 값에 대한 차이에 대한 질문 글을 볼 수있었습니다. 이에 대한 답변은 SizeEstimator는 JVM 힙에서 객체가 차지하는 바이트수를 반환하는데 연관된 값까지 같이 엮어서 알려준다는 내용이었습니다. 하지만 해당 내용에서 web UI를 통해서 확인한 데이터 사이즈는 4GB인데 SizeEstimator를 통해서 확인한 값은 100MB로 되어있어 오히려 SizeEstimator로 확인되는 값이 더 커야하지 않는지 잘 모르겠네요..🤨
https://stackoverflow.com/questions/49492463/compute-size-of-spark-dataframe-sizeestimator-gives-unexpected-results
Memory Management
Spark에서 메모리는 실행, 저장이라는 두 범주로 나눌 수 있습니다. 실행, 저장 메모리는 통합된 region을 공유하는데 이에 따라서 실행 메모리가 사용되지 않으면 저장이 사용 가능한 모든 메모리를 차지할 수 있는식입니다.
- Execution memory
실행 메모리는 셔플, 조인, 정렬, 집계 연산에서 사용되는 메모리입니다.
- Storage memroy
클러스터 전체에 내부 데이터를 캐싱하고 전파하는 데 사용되는 메모리를 의미합니다
Data Structure Tuning
메모리 소비을 개선하기 위해서는 포인터 베이스 데이터 구조처럼 오버헤드를 높이는 기능이나 wrapper 개체 사용을 줄이는 것입니다.
- HashMap같은 콜렉션 클래스 대신 개체 배열 구조나 기본 유형 사용하는 데이터 구조 설계
- 작은 개체와 포인터 많이 포함된 중첩 구조 지양
- 키 문자열 대신 숫자 타입 또는 ENUM 개체를 사용
- RAM이 32GiB 미만인 경우 JVM 플래그를 설정하여 -XX:+UseCompressedOops포인터를 8바이트가 아닌 4바이트로 설정
Garbage collection Tuning
Spark 작업을 할때 메모리에 데이터를 저장하고 처리하기 때문에 효율적인 메모리 관리가 필요합니다. GC는 이때 사용하지 않는 객체들을 정리해서 메모리를 확보하는 역할을 합니다.
JVM에서 메모리를 관리하는데에는 다음 기본 개념을 알 필요가 있습니다. Java Heap 스페이스는 Young, Old라는 두 영역으로 나뉩니다. Young generation은 단기로 유지되는 개체를 다루고 Old는 반대로 장기로 유지되는 개체입니다. 여기서 더 나아가서 Young은 Eden, Survivor1, Survivor2라는 세가지 영역으로 나뉩니다. 간단하게 GC 과정을 묘사한다면 Eden이 꽉차면 Eden 및 Survivor1에서 살아있는 개체가 Survivor2에 복사됩니다. 그러면 Survivor 영역들은 스왑됩니다. 만약 개체가 오래되었거나 Survivor2 영역도 가득 찼다면 Old로 이동됩니다. Old도 꽉 찼다면 전체 GC가 실행됩니다.
RDD 대규모 변경이 있는 경우 과도한 GC 작업은 애플리케이션 성능 저하를 야기할 수 있습니다. Young 개체를 위한 공간을 확보하기 위해 이전 개체를 제거해야할 때 모든 개체를 추적하여 찾아내는 식은 빈번한 메모리 할당 및 해제가 발생해 GC 오버헤드가 커지게 됩니다. GC 비용은 Java 개체 수에 비례하기 때문에 더 적은 수의 객체가 포함된 데이터 구조를 사용하거나 다른 방법으로 오버헤드를 낮추는 것이 좋습니다. GC 튜닝의 목적은 수명이 장기적인 RDD만 Old에 저장되고 Young generation은 수명이 짧은 개체를 저장할 수 있을만큼 충분한 크기를 확보하는데 있습니다. GC 튜닝의 단계는 다음과 같습니다.
1. GC가 발생하는 빈또와 GC에 소요되는 시간 파악
Spark Job에 다음 Java 옵션을 전달하면 Spark Job이 실행되면 GC가 발생할때마다 워커에 남는 로그를 확인할 수 있습니다.
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
2. minor collection이 많지만 major GC는 많지 않은 경우 Eden에 더 많은 메모리를 할당합니다.
3. 더 적은 개체를 캐싱하는 방향이 작업 실행 속도를 낮추는것보다 낫기때문에 OldGen이 거의 꽉차면 `spark.memory.fraction` 설정을 낮춰서 캐싱을 위한 메모리 사용량을 낮춥니다.
4. 데이터 블록을 통해 메모리 사용량 산정하기. 작업이 HDFS에서 데이터를 읽는 경우 작업에 사용되는 메모리 양은 HDFS에서 읽은 데이터 블록의 크기를 사용하여 추정할 수 있습니다. 압축이 풀린 블록의 크기는 블록 크기의 2-3배인 경우가 많습니다. 3-4개의 태스크에 해당하는 작업 공간이 필요하고 HDFS 블록 크기가 128MiB인 경우 Eden의 크기는 태스크작업공간*압축풀린블록크기= 4*3*128MiB입니다.
GC 튜닝의 영향도는 Spark 애플리케이션과 사용가능한 메모리량에 달려있습니다. high level의 전체 GC가 발생하는 빈도를 관리하는 것이 오버헤드를 줄일 수 있습니다.
executor에 대한 GC 튜닝 플래그는 Spakr Job 구성에서 다음 설정을 통해 지정할 수 있습니다.
- spark.executor.defaultJavaOptions OR spark.executor.extraJavaOptions
마무리..
위에서 Spark 성능 향상을 위해서 직렬화 등 데이터 구조, 메모리 관리, GC 튜닝 등 검토해볼 수 있는 다양한 지점을 소개합니다. spark 튜닝에 대한 공식문서의 마무리 요약에서는 대부분 퍼포먼스 이슈들은 Kryo serialization으로 교체하고 persist 데이터를 serialized 형식으로 저장하는거로 보통 해결할 수 있다고 합니다. 사실 이번 포스트는 직접 Spark 튜닝을 해보면서 알아가는 내용보다는 앞으로 해볼 수 있는 작업이기에 한번 미리보기로 개념만 봤습니다. 그래서 아직 추상적인 인식으로만 남는데 앞으로 spark 작업을 하드하게 해보면서 확인해볼 수 있을거 같습니다..
참고 링크
spark memoryOverhead 설정에 대한 이해
2022.04.02 추가 spark memoryOverhead 설정에 대한 이해 (2)가 등록되었습니다. 목차 Spark 버전에 따른 설정명 우선 Spark 버전에 따른 설명명부터 알아보자. Spark 2.2까지: spark.yarn.executor.memoryOverhead Spark 2.3
jason-heo.github.io
Spark Memory Management
1. Introduction Spark is an in-memory processing engine where all of the computation that a task does happens in memory. So, it is important to understand Spark Memory Management. This will help us develop Spark applications and perform performance tu
community.cloudera.com
'DataEngineering' 카테고리의 다른 글
| dbt sql modeling (0) | 2025.03.02 |
|---|---|
| Trino 아키텍처와 에러 파악하기 (3) | 2024.11.10 |
| [Spark] Spark run in Cluster Mode-YARN (1) | 2024.02.04 |
| [Airflow] Operators (0) | 2024.01.21 |
| Airflow Concept (0) | 2023.12.24 |